Alexey Grigoriev, Machine Learning Engineer, ID R&D
Despite the current progress, computer vision still falls short of human vision, which is remarkably fast at perceiving and understanding a scene and its high-level structure. It typically takes a human just milliseconds to look at a scene, pass information to the brain, and process a huge amount of data about the scene and the objects in it: including shapes, colors, distances, etc. Humans often only need to take one look at an image to understand the basic idea of it. For instance, you can imagine a photo of a familiar place such as an office. The human eye can easily qualify it as such by recognizing familiar objects: tables, chairs, computers, whiteboards, and people in business attire.
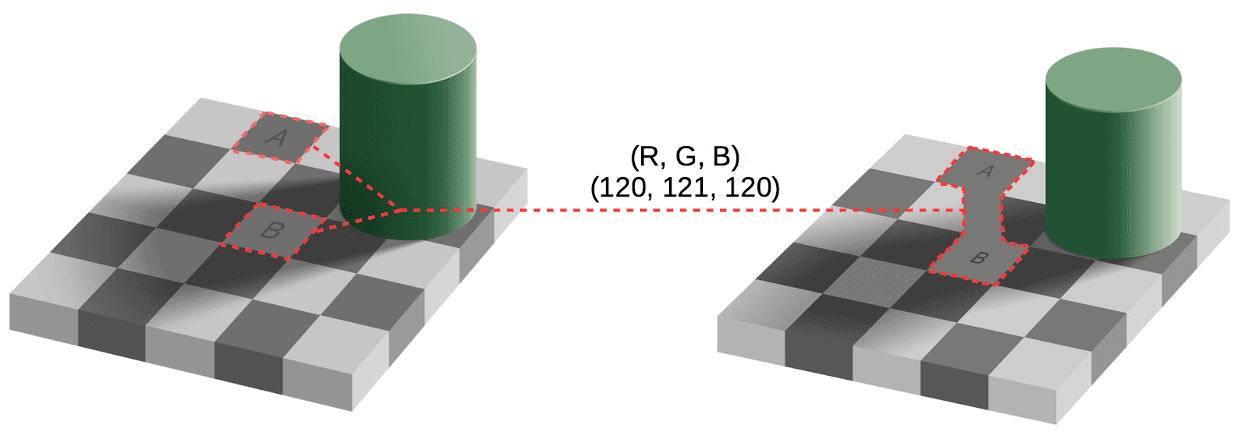
However, human vision can be tricked. For example, take a look at the famous picture below. As you can see, the color of the squares marked A and B appears to be different, but in fact, it is the same. You can verify it by yourself. Just download this image, open it in any image editing program and pick the color in square A or B. In the RGB color space, the color will be (120, 121, 120). Because square B is located in the shadow of the green cylinder, the brain sends a signal to see it more brightly than square A. Such brightness compensation gives us an illusion that the squares are different colors.
You may wonder, what about Computer Vision?
How fast does a computer understand an image? Well, it’s complicated. Understanding an image is one of the most complex tasks in computer vision and, as such, is divided into subtasks: object detection, depth estimation, event categorization, etc. Classic computer vision provides a wide range of methods for simplifying scene-recognition. However, these methods are not as efficient as deep learning-based methods, especially in terms of computational complexity, robustness, and accuracy. The deep learning breakthrough has revolutionized and accelerated modern computer vision. For instance, in a typical classification task, we use a deep convolutional neural network to process an image and acquire the object class. The processing speed depends on the GPU-unit and network we have chosen, but on average it may take about 0.02 seconds. However, this is only one operation for obtaining information about object class. We still lack the object’s location in the scene, distance from the camera to the object, and other information that is significant for scene understanding. To acquire more information we need to use a multi-task network, a set of task-specific networks, or design a new network that may increase computational complexity.
Fighting Spoofing Attacks With Computer Vision
Advancements in the computer vision field help to resolve tasks that were considered impossible to solve for a long time. At ID R&D we employ computer vision to solve one of the most exciting tasks in biometrics – facial liveness detection (or face anti-spoofing). Liveness distinguishes between real and spoofed faces in an image, where the spoof may be a 2d/3d-mask, mobile/screen-replay, printed photo, etc.
The liveness capability is significant as more of our daily interactions – from working to shopping to banking – are performed online and remotely. To support digital transformation efforts many companies, including banks and telcos, are leveraging facial recognition for onboarding and authentication. However, to prevent unauthorized access, a facial biometric system has to be equipped with a liveness detection algorithm. A face recognition system automates the determination of a match. To the face recognition system, there isn’t always a difference between a picture of a human and a picture of a picture when matching. Thus, an attacker may use a photo of a person to get access to his bank account or other private information. Moreover, we can not underestimate the creativity of the attacker. He may use an expensive video camera or display to shoot a video-replay with high quality. Or, he could buy a high-quality 3d-mask of the target person and use it to trick a face recognition system. Liveness is needed to ensure the match is determined based on a live human being present during capture. Of course, you can hire a person to manually analyze photos, but such a solution raises a lot of questions. How many photos can one person check in one day? How many workers do you need to hire? How good is this person at spoof spotting? Let’s take a look at the picture from our recent It’s Alive, Or Is It? blog post. How many spoofs and live images can you spot here?

The AI-based system successfully detected all the spoofs in this picture. All of them are spoofs! In such cases, AI-based systems can work much better than human vision.
How Computer Vision Works to Detect Liveness
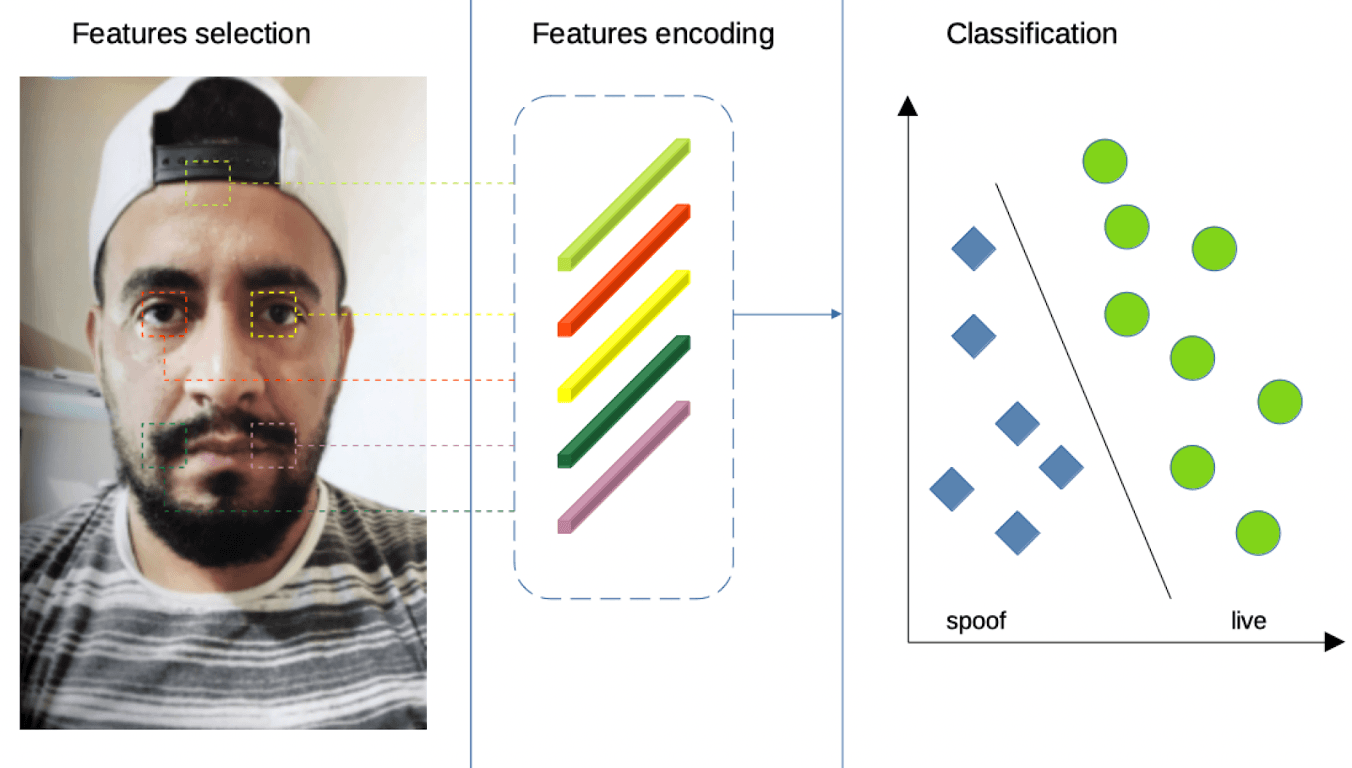
Computer vision provides a wide range of methods to distinguish between spoofs and live photos. How does it work? When designing a liveness detector, an engineer must first analyze the various types of images in a training dataset and determine the parts of each image that are important for detecting a spoof. For instance, the borders of a phone or mask, moire or reflection on the screen, etc. Second, an engineer needs to select an algorithm to convert each of the important parts of an image into an internal computer representation, which is known as a feature. Finally, features are extracted from the training dataset and used to train the spoof detector.
Classic methods are highly reliant on the feature engineering process. Designing the “right” features is a critical part of building a liveness detector but there are some challenges. First, it is difficult to select suitable features for a large and diverse dataset. Some features might work well for one class of attacks, and work poorly for another. To increase the quality of the liveness detector, one may select features that work well for a wide range of attacks. However, the more features that are selected, the greater the chance of false rejections. Also, different capturing photo conditions can dramatically affect the quality of the liveness detector. Hand-crafted features are sensitive to illumination or background changes. Second, some features may work well only in a specific domain scope. For instance, 2d-masks may have a specific texture pattern, which is a trait of the material it has been made from. But changing the material will remove this pattern from the 2d-mask, making the features that relied on it useless. Third, the generalization ability of hand-crafted features is limited by available training and validation datasets. While the detector may perform well on available data, accuracy may be poor on unseen attacks. These issues make creating a quality liveness detector based on hand-crafted features almost impossible, especially one that works in different environments.
Nowadays, deep learning-based methods significantly improve the quality of liveness detectors and have changed the process of creating one. Modern CNN can extract the most important features from an image. Moreover, the backpropagation algorithm forces the network to `learn` which part of an image is important to classify the input sample as live or as a spoof. The more data you have, the higher the network accuracy — but there is an underlying issue. The more biased your data is, the more biased the network will be. Thus, data collection is critical to creating a high-quality liveness detector, especially if you want it to work across different demographic groups. At ID R&D we pay significant attention to reducing bias in data.
Modern GPU/TPU-units make it possible to train networks in a shorter period of time. Due to the properties of the neural networks, the extracted feature is more robust to scale, illumination, and background changes. It is also more robust to object position on the image and image quality. Small degradations in image quality, changes in illumination, or the position of an object in an image, do not have an impact on network accuracy. Such efficiency and robustness make neural networks a desirable choice for a wide range of computer vision solutions.
In contrast to hand-crafted features, CNN-based liveness detectors are more suitable for real-world applications. It is especially significant for passive liveness solutions when we do not want to force a user to take a photo under predefined conditions. At ID R&D we employ the latest advances in deep learning and GPU/TPU-units to develop a powerful liveness detector, which works in a wide range of conditions with best-in-class accuracy. Watch the demo of our IDLive™ Face product.