
IDVoice: Innovative Voice Verification Software from ID R&D
ID R&D’s core voice biometrics product, IDVoice, incorporates industry-leading research, deep expertise in voice, and artificial intelligence to deliver a robust speaker recognition engine with unmatched functionality and accuracy. Features include language independence, advanced voice activity detection for improved speech processing, and speaker diarization for isolation of a specific speaker’s audio stream.
ID R&D was ranked #1 in the Short Duration Speaker Verification Challenge (SdSV) which specifically tests performance in the microphone channel. We also demonstrated strong performance in the telephone channel in the NIST Speaker Recognition Evaluation.
Text-Dependent and Text-Independent Speaker Recognition
Voice biometrics is the science of using a person’s voice as a uniquely identifying characteristic for the purpose of authentication and/or personalizing the user experience. The technology is referred to in a variety of ways including voice verification, speaker verification, speaker identification and speaker recognition.
Text-Independent Voice Verification does not depend on the person speaking a particular passphrase. Text-Dependent Voice Verification requires the user to enroll using a specific phrase. Unlike a password, this phrase is not secret. IDVoice enables both options depending on your use case and in some scenarios they may be used together.
Use Cases for Speaker Verification
A typical text-independent speaker verification use case is authenticating a caller while they are speaking with a call center agent, or even in the IVR. But voice biometrics isn’t just for contact centers. Increasingly, voice is used as an authentication factor for mobile application login – often in conjunction with face biometrics and something the user has, such as their device. Additionally, speaker recognition is being used to bring frictionless security and personalization to conversational interfaces, messaging apps, and IoT devices ranging from smart speakers to connected cars.
IDVoice works perfectly, even in the noisiest environments
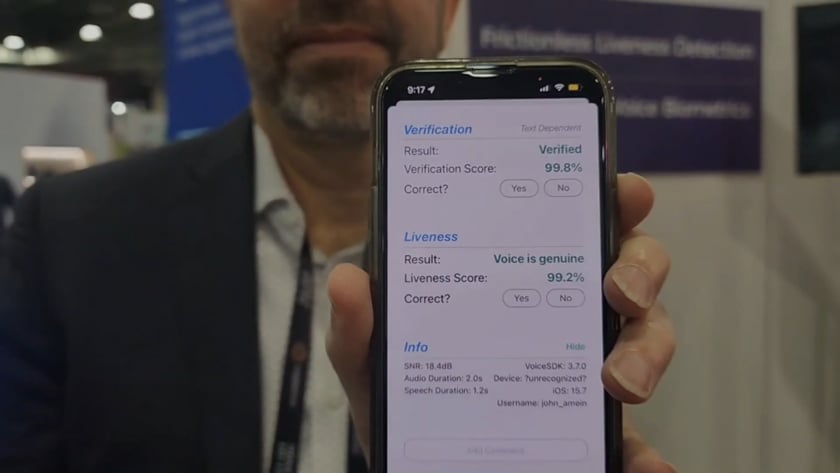
Voice biometrics have to work even when there’s lots of noise in the background. Here is IDVoice speaker recognition working on a very loud show floor at Money20/20 USA 2022 in Las Vegas. Even with a rock band playing indoors nearby, IDVoice is still able to accurately verify and check liveness.
The science behind IDVoice Speaker Recognition
IDVoice combines proprietary text- and language-independent technology based on deep neural networks (DNN). The architecture is designed to support multiple outputs for multiple use cases:
- Ultra-short keywords starting at 0.1 sec in length
- Short commands/requests from 3-5 seconds in length
- Complex requests including pre-defined keywords and free-speech
- Telephone conversations
Proprietary implementation of the DNN layers and compression allows ID R&D to achieve a small footprint, as well as latency below 150 ms even on mobile devices. Latency is further reduced below 40 ms when utilizing a Neural Processing Unit (NPU).
Low error rates are consistently achieved even with far-field microphones and in noisy environments. ID R&D’s neural network technology is trained with noisy data for better real-world performance.
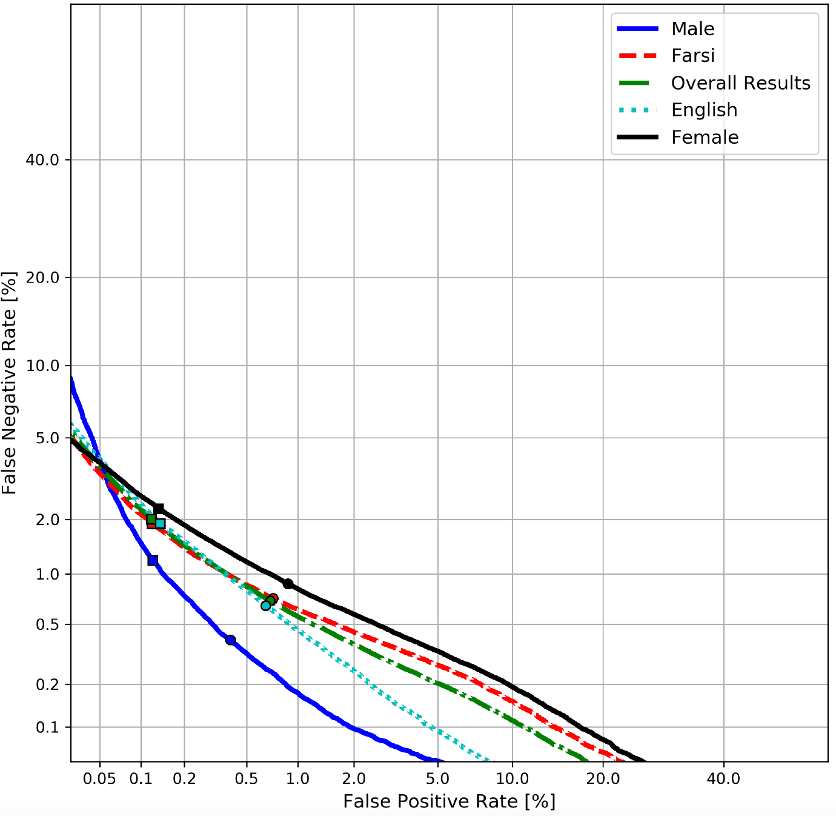
Official results for IDVoice (ranked 1st) at the Short-duration Speaker Verification (SdSV) Challenge 2021 Text-Independent Speaker Verification
Getting started with IDVoice Speaker Verification
IDVoice is delivered as an SDK for easy integration with your existing applications or product offerings. The speaker identification software can be combined with ID R&D’s IDLive Voice for voice anti-spoofing, as well as with additional biometric modalities to fit a wide range of use cases and solutions. Deploy IDVoice on mobile clients, servers, private clouds, and embedded systems. ID R&D supports Linux, Windows, iOS, and Android platforms, and is also available as a Docker image.
Learn more about IDVoice
IDVoice Speaker Recognition Software Features
- Text-dependent and text-independent modes
- Use with any language – no tuning or training data is necessary to operate in any country
- Industry-leading matching algorithms for enrollment, verification and identification
- Accurate signal quality estimation including signal-to-noise ratio and net speech length
- Fast voice activity detection and speech endpoint detection for higher accuracy
- Supports model enrichment, where new voice templates are merged into previous templates to adapt to changes in a user’s voice over time
- Accurate diarization of monophonic audio
- Supports continuous voice verification in a conversational interface or with a human agent
- Easily scaled on premises or in private clouds due to its functional, stateless architecture.
- Configurable software footprint with options for embedded systems and low-power devices
- Cross-channel compatibility, no retraining and no re-enrollments when using across applications and devices
- Ability to run on the device for a complete offline solution for mobile apps
- FIDO-compatible SDK for mobile devices
- Robust documentation and code examples
- C, C++, C#, Python and Java desktop interfaces for server deployments
- REST API
Ready to learn more about ID R&D’s top-rated voice recognition biometric software?
Contact us with your questions or availability for a meeting with one of our voice verification experts.
Benefits of Voice Verification
- Minimize the use of weak passwords and strengthen security

- Reduce user frustration with password resets, obscure security questions and security codes
- Improve contact center efficiency with faster authentication and fight Account Takeover fraud
- Use with ID R&D’s passive voice liveness to combat spoofing attempts
- Deploy voice and face biometrics together to further strengthen security without adding friction to the UX
- Personalize and secure voice-enabled apps, smart devices, embedded systems
Securing Voice Verification with Voice Anti-Spoofing
When it comes to authentication, biometric data used for matching is stored as an encrypted template apart from a user’s personally identifiable information – usually in your cloud, on your premises, or on the user’s device. This template is meaningless to anyone who obtains it. The real concern is how easily and quickly a fraudster can find your photo, a video, or a recording of your voice online and use it to “trick” a biometric system into thinking it’s seeing or hearing you. This is called a spoofing attack, or presentation attack, and it is prevented using a technology called liveness detection.
ID R&D’s IDLive Voice provides the #1 rated anti-spoofing for voice biometrics. The product works in the background to distinguish between a real person and a presentation attack without any actions or additional effort from the user. Consequently, because the liveness detection is imperceptible to users without indication of when it’s happening or what it’s looking for, it offers no clues to fraudsters on how to break it. Learn more about IDLive Voice anti-spoofing.