
Here’s what you need to know to protect your business and yourself.
Video deepfakes are making news headlines — from their potential to swing elections to the ability to revive old movies with new stars. But another type of deepfake called voice cloning has emerged. How real is this threat to the security of the voice-enabled world and what can be done to mitigate these risks?
First, what is voice cloning?
Voice cloning is the creation of an artificial simulation of a person’s voice. Today’s AI software methods are capable of generating synthetic speech that closely resembles a targeted human voice. In some cases, the difference between the real and fake voice is imperceptible to the average person.
How voice clones are created
Online AI text-to-voice software began with using computers to synthesize voice. Text-to-Speech (TTS) is a decades-old technology that converts text into synthetic speech, enabling voice to be used for computer-human interaction.
In the past, there have been two approaches to TTS. The first, Concatenative TTS, uses audio recordings to create a library of words and units of sound (phonemes) that can be strung together to form sentences. While the output is high quality and intelligible, it lacks the emotion and inflection found in natural human speech. When using Concatenative TTS, every new speech style or language requires a new audio database. And certainly the effort to clone any individual voice using this method requires enormous investment, typically only done to support a branded voice.
The second approach is Parametric TTS, a method that uses statistical models of speech to simplify creating a voice, reducing the cost and effort compared to Concatenation. However, the effort for creating any single voice has historically been expensive, and the results clearly not human.
Today, Artificial Intelligence (AI) and advances in Deep Learning are advancing the quality of synthetic speech. Applications for TTS are now commonplace. Everyone who has interacted with a phone-based Interactive Voice Response system, Apple’s Siri, Amazon Alexa, car navigation systems, or numerous other voice interfaces, has experienced synthetic speech.
AI-enabled synthetic voice
If you are familiar with the concept of a video deepfake, online AI voice cloning software is the speech equivalent. With as little as a few minutes of recorded speech, developers can build an audio dataset and use it to train an AI voice model that can read any text in the target voice.
The task is now significantly easier thanks to a variety of neural network-powered tools such as Google’s Tacotron and Wavenet or Lyrebird, which enable virtually any voice to be replicated and used to “read” text input. The quality of the output is steadily improving, as demonstrated by this voice clone of podcaster Joe Rogan. The deep learning engineers at Dessa who created the clone also set up a quiz. Take it to see if you can spot the fake Rogans.
Neural network-based TTS models mimic the way the brain operates and are extraordinarily efficient at learning patterns in data. While there are different approaches to the use of deep learning in synthetic voices, most result in better pronunciation of words, as well as capturing subtleties like speed and intonation to create more human-like speech.
It’s important to note that the tools mentioned above and others like these were not created for the purpose of fraud or deception. But the reality is that business and consumers need to be aware of new threats associated with online AI voice cloning software. We explore some of the uses — for good and bad — below.
How are voice clones used?
First, the bad…
Voice is a unique personal identifier that is readily accessible to fraudsters. This is certainly true for public figures including celebrities, politicians and business leaders, but the reality is that anyone could be a target. Online videos, speeches, conference calls, phone conversations and social media posts can all be used to gather the data needed to train a system to clone a voice.
Voice biometric spoofing — Voice is a unique identifier and reliable measure for biometric security. However, criminals can use presentation attacks including recorded voice, computer-altered voice and synthetic voice, or voice cloning, to fool voice biometric systems into thinking they hear the real, authorized user and grant access to sensitive information and accounts.
Phishing scams – Online AI voice cloning software also enables a new breed of phishing scams that exploit the fact that a victim believes they are talking to someone they trust. Last year, a UK-based CEO was tricked into transferring more than $240,000 based on a phone call that he believed was from his boss, the CEO of the organization’s German parent company.
Scams like this are an evolution of email scams where an executive email is spoofed in attempt to have the recipient divulge bank account numbers, credit card information, passwords and other sensitive data. Now scammers, armed with voice clones, are using phone calls and voicemail. And the attacks aren’t just threatening businesses. In a new breed of the “grandma scam” criminals are posing as family members who need emergency funds.
Misinformation – Fake news and similar forms of misinformation pose a serious threat. Many of us are familiar with how manipulated video to impact the political landscape. For example, a popular video shows Barack Obama calling Trump a – well, let’s just say it wasn’t very nice. It also wasn’t real. AI-based text-to-speech software technology will further fuel these efforts to sway public opinion, drum up fake campaign donations, defame public figures, and more. On the business front, consider how manipulated executive or public figure statements could affect the stock market.
Evidence – Synthetic voices and other deepfakes could be used to create fake evidence that impacts criminal cases. While checks exist to validate audio and video evidence presented in court, preventing these tactics from influencing testimony based on what people believe they saw or heard may be a challenge.
Blackmail and bullying – Manipulated video and audio of people doing or saying things they didn’t do our say can be used for online bullying and threats to expose fake, embarrassing content if victims refuse to pay a fee.
Now, the good…
Many positive, exciting use cases are emerging.

Education – Cloning the voices of historical figures offers new opportunities for interactive teaching and dynamic storytelling. For example, on November 22, 1963 President Kennedy was on his way to give a speech in Dallas when he was assassinated. We can now hear that speech in his own words using deepfake technology. In another amazing use of the AI deepfakes, visitors to the Dalí Museum in St. Petersburg are greeted by Salvador Dali himself. Dali interacts with guests using actual quotes and created commentary, and even takes selfies with them. See the video and learn more about how Dali was brought back to life through the power of AI.
Audiobooks – Using AI voice cloning software, celebrity voices can be used to narrate books, autobiographies can be read by the author, and historical figures can tell their stories in their own voices. The result is an immersive, high-quality listening experience.
Assistive Tech – Synthetic voices can be used to assist persons with disabilities or health issues that impact their speech. For example, people who are Deaf or suffering from disorders like Parkinson’s Disease or ALS can enhance their ability to communicate using a synthetic version of their voice and TTS.
Detecting voice deepfakes
As voice technology continues to improve, having technology that can recognize and stop the use of fake speech for fraud and deception is imperative.
Voice anti-spoofing, also called voice liveness detection, is a technology capable of distinguishing between live voice and voice that is recorded, manipulated or synthetic. Many of today’s fakes are imperceptible to the human ear, but can be detected by AI-based software trained to identify artifacts that aren’t present in a live voice.
Technologies that detect AI voice cloning software were initially created to solve the problem of voice biometric spoofing. Where voice biometrics match a person’s voice to the voice template on file, anti-spoofing technology checks to ensure the voice is live. The technology will continue to adapt to address additional use cases as voice cloning fraud becomes more prevalent. The topic was even the focus of a recent FTC workshop with participants from ID R&D DARPA, University of Florida, MIT Sloan School of Management, and Microsoft’s Defending Democracy program.
Voice Anti-Spoofing Industry Challenge
The ASVspoof.org Automatic Speaker Verification Spoofing and Countermeasures Challenge is a competitive evaluation that aims to promote the development of effective anti-spoofing technologies and make speaker verification systems more secure. The 2019 challenge was the first to focus on countermeasures for all three major attack types: TTS, voice conversion and replay attacks.
For ASVspoof 2019, Google AI and Google News Initiative made a synthetic speech dataset consisting of thousands of phrases available to participants.
The results of the 2019 challenge can be viewed here.
ID R&D’s anti-spoofing voice technology returned the lowest Equal Error Rate (EER), a metric that measures a solution’s accuracy in distinguishing genuine speech from spoofed speech. The EER is the point at which the two types of errors, falsely accepting a spoof as real and falsely labeling a real voice as a spoof, are equal. With an EER of .22%, ID R&D, or Team T05 in the green line in the accompanying graph, scored best on an evaluation dataset.
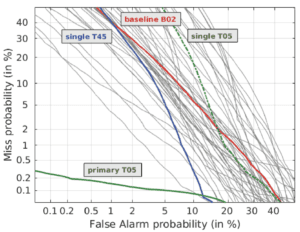
How ID R&D Fights Deepfakes
ID R&D offers industry-leading voice biometric authentication but believes that is only part of a comprehensive authentication solution. As such, we’ve invested heavily in R&D to deliver the #1 rated voice anti-spoofing technology to ensure the integrity of the voice biometrics and fight fraud. Learn more about our voice anti-spoofing technology today. If you would like to talk about how the technology can further improve authentication or other areas of your business, contact us.